論文情報
- タイトル: High-Resolution Image Synthesis with Latent Diffusion Models
- 著者: Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer
- 発表: CVPR 2022 (Oral)
- arXiv: 2112.10752
- 通称: Stable Diffusion の基礎論文
z-image-turboをはじめとするStable Diffusion系モデルは、すべてこの論文のアーキテクチャに基づいています。AI画像生成を理解する上で最も重要な論文です。
どんなもの?
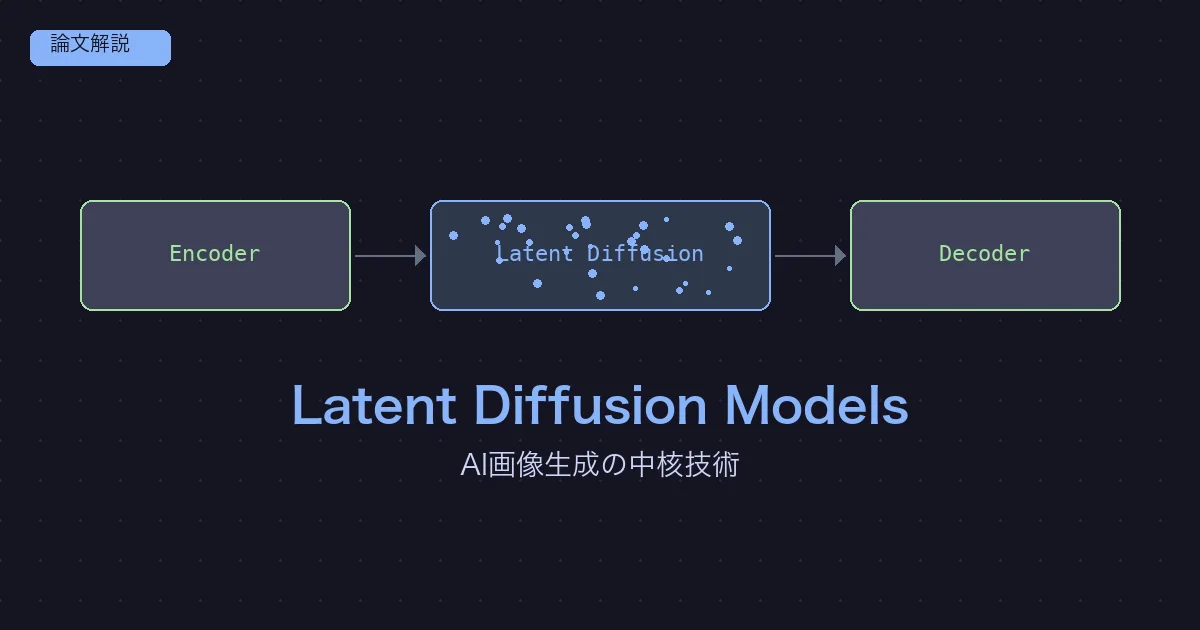
画像生成の拡散過程を画像のピクセル空間ではなく、圧縮された潜在空間(Latent Space)で行う手法です。
従来の拡散モデル(DDPM等)はピクセル空間で動作していたため、高解像度画像の生成には膨大な計算コストが必要でした。LDMは事前学習したAutoEncoderで画像を低次元の潜在表現に圧縮し、その潜在空間で拡散過程を実行することで、計算コストを大幅に削減しつつ高品質な画像を生成します。
先行研究と比べてどこがすごい?
ピクセル空間の拡散モデル(DDPM等)
- 512x512の画像をそのまま拡散 → GPU日数レベルの計算コスト
- 高解像度化が実質的に困難
- 品質は高いが実用性に課題
GAN(Generative Adversarial Networks)
- 高速な生成が可能
- モード崩壊(特定のパターンしか生成できなくなる)のリスク
- 学習が不安定
LDMのブレイクスルー
| 比較項目 | DDPM(ピクセル空間) | GAN | LDM |
|---|---|---|---|
| 計算コスト | 非常に高い | 低い | 大幅に削減 |
| 画質 | 高い | 高い | 高い |
| 学習安定性 | 安定 | 不安定 | 安定 |
| 多様性 | 高い | モード崩壊あり | 高い |
| 条件付け | 困難 | 困難 | Cross-Attentionで柔軟 |
LDMは「拡散モデルの品質・安定性」と「GANの計算効率」の良いとこ取りを実現しました。
技術や手法のキモはどこ?
LDMのアーキテクチャは3つのコンポーネントで構成されています。
1. 知覚圧縮(Perceptual Compression): AutoEncoder
画像をピクセル空間から潜在空間に変換するコンポーネントです。
入力画像 (512×512×3)
↓ エンコーダ E
潜在表現 z (64×64×4) ← ここで拡散を行う
↓ デコーダ D
出力画像 (512×512×3)
- 圧縮率: 512×512×3 = 786,432次元 → 64×64×4 = 16,384次元(約48倍の圧縮)
- 知覚的に重要な情報は保持し、高周波ノイズを除去
- KL正則化またはVQ正則化で潜在空間の構造を整える
この圧縮によって、拡散過程の計算コストが劇的に削減されます。
2. 潜在空間での拡散過程: U-Net
圧縮された潜在空間で、ノイズの付加(拡散)と除去(逆拡散)を行います。
拡散過程(学習時):
z₀ (元の潜在表現)
→ z₁ (少しノイズを追加)
→ z₂ (もう少しノイズ)
→ ...
→ z_T (完全なノイズ)
逆拡散過程(生成時):
z_T (ランダムノイズ)
→ z_{T-1} (少しノイズを除去)
→ ...
→ z₀ (クリーンな潜在表現)
→ デコーダD → 出力画像
U-Netが「このノイズ画像からどれだけノイズを除去すべきか」を予測します。
3. Cross-Attentionによるテキスト条件付け
LDMの革新的な点は、Cross-Attention層によって柔軟な条件付けを実現したことです。
プロンプト "a Japanese woman in a cafe"
↓
CLIPテキストエンコーダ → テキスト埋め込み (77×768)
↓
U-Netの各層でCross-Attention
↓
テキストに条件付けされたノイズ除去
Cross-Attentionの仕組み:
- Query (Q): U-Netの中間特徴量(画像側の情報)
- Key (K): テキスト埋め込み(テキスト側の情報)
- Value (V): テキスト埋め込み
Attention(Q, K, V) = softmax(QK^T / √d) × V
これにより、U-Netの各空間位置が「テキストのどの部分に注目すべきか」を学習します。例えば、cafeに対応する領域にはカフェの要素が生成されます。
CLIPのテキストエンコーダの仕組みについてはCLIP論文解説を参照してください。
学習の2段階化
LDMは2つのフェーズに分けて学習します:
フェーズ1: AutoEncoderの学習
- 画像の圧縮・復元を学習
- 潜在空間の構造を獲得
フェーズ2: 拡散モデルの学習
- フェーズ1で学習済みのAutoEncoderを固定
- 潜在空間での拡散・逆拡散を学習
- Cross-Attention層でテキスト条件付けを学習
この分離により、各フェーズが独立して最適化でき、学習が安定します。
ダウンサンプリング係数の選択
論文では異なる圧縮率(f = 1, 2, 4, 8, 16, 32)を比較検証しています。
| 係数 f | 潜在空間サイズ(512入力) | 結果 |
|---|---|---|
| f = 1 | 512×512 | ピクセル空間と同じ。遅い |
| f = 4 | 128×128 | 品質と速度のバランスが最良 |
| f = 8 | 64×64 | 高速だが細部がやや失われる |
| f = 16 | 32×32 | 高速だが品質低下 |
| f = 32 | 16×16 | 詳細が大幅に失われる |
Stable Diffusionではf = 8が採用されています。
どうやって有効だと検証した?
定量評価
複数のデータセットで最先端またはそれに匹敵するFIDを達成:
| データセット | FID | 備考 |
|---|---|---|
| CelebA-HQ (256×256) | 5.15 | 顔画像生成 |
| FFHQ (256×256) | 4.98 | 高品質顔画像 |
| LSUN-Churches (256×256) | 4.48 | 教会画像 |
| LSUN-Bedrooms (256×256) | 2.95 | 寝室画像 |
計算コスト比較
ピクセル空間の拡散モデルと比べて、推論速度が大幅に向上:
- LDM-4: ピクセル空間モデルの約4〜8倍高速
- LDM-8(Stable Diffusion): さらに高速
- V100 GPU 1台で実用的な速度で生成可能
多様なタスクへの適用
LDMは画像生成に限らず、以下のタスクでも検証されています:
- テキスト→画像生成: Cross-Attentionでテキスト条件付け
- 画像修復(Inpainting): マスク領域の補完
- 超解像: 低解像度から高解像度への変換
- レイアウト→画像: バウンディングボックスから画像生成
- 意味的画像合成: セグメンテーションマップから画像生成
議論はある?
制限事項
- 細部の再現性: 潜在空間への圧縮で微細なディテール(文字、指など)が失われることがある
- 潜在空間のボトルネック: 圧縮率が高いと画質が低下。低いと計算コスト削減効果が薄れる
- 2段階学習の複雑さ: AutoEncoderの品質が全体の品質に影響する
- テキスト条件の限界: CLIPの75トークン制限により、長い記述の表現に限界がある
指の問題
AI画像生成で頻出する「指の本数がおかしい」問題は、LDMの潜在空間圧縮に一因があります。潜在空間では指のような微細な構造の情報が失われやすく、正確な再現が困難です。これがネガティブプロンプトで missing fingers, extra fingers を指定する理由です。
次に読むべき論文は?
| 論文 | 関連性 |
|---|---|
| DDPM: Denoising Diffusion Probabilistic Models (Ho et al., 2020) | 拡散モデルの基礎。LDMのベースとなった手法 |
| CLIP (Radford et al., 2021) | テキスト条件のエンコードに使用 → CLIP論文解説 |
| Classifier-Free Diffusion Guidance (Ho & Salimans, 2022) | LDMと組み合わせて使われるガイダンス手法 → CFG論文解説 |
| SDXL (Podell et al., 2023) | LDMの改良版。より高品質な画像生成 |
| U-Net (Ronneberger et al., 2015) | LDMの拡散モデルで使われるアーキテクチャ |
この論文がAI画像生成に与えた影響
LDMはStable Diffusionとして公開され、AI画像生成を一般に普及させた最も重要な論文です。オープンソース化されたことで、z-image-turboを含む多数の派生モデルが生まれました。
ComfyUIのワークフローで設定する「KSampler」のステップ数やサンプラーは、この論文の逆拡散過程のパラメータに対応しています。
関連記事
- z-image-turboとは — LDMベースの高速画像生成モデル
- ComfyUIワークフロー — LDMのパラメータを制御するUI
- プロンプトの基本法則 — CLIPトークン制限とプロンプトの語順
- CLIP論文解説 — テキスト条件付けの基盤技術
- CFG論文解説 — ネガティブプロンプトの理論