論文情報
- タイトル: Learning Transferable Visual Models From Natural Language Supervision
- 著者: Alec Radford, Jong Wook Kim, Chris Hallacy, et al. (OpenAI)
- 発表: ICML 2021
- arXiv: 2103.00020
AI画像生成でプロンプトを書くとき、なぜ英語のテキストが画像に変換されるのか? その根幹にあるのがCLIPです。プロンプトの基本法則で述べた「75トークン制限」もCLIPに由来しています。
どんなもの?
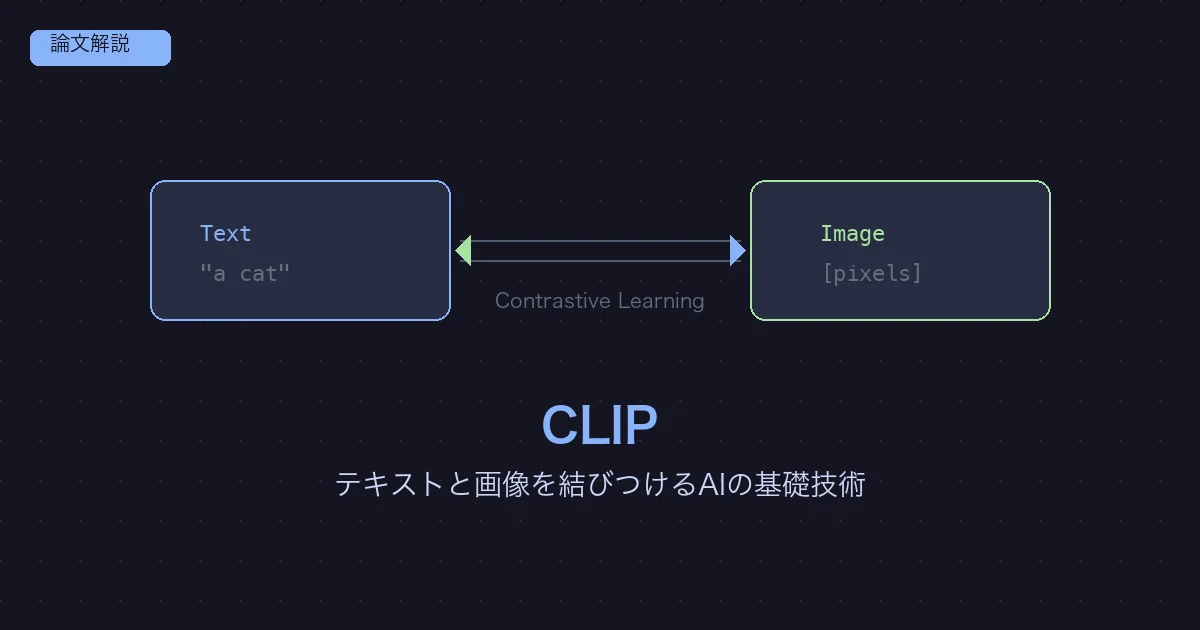
CLIPはテキストと画像の意味的な対応関係を学習するモデルです。
- 「猫の写真」というテキストと、実際の猫の写真が「似ている」と判断できる
- 「夕焼けの海」というテキストに最も合う画像を、大量の画像から選べる
4億組のテキスト-画像ペア(WIT-400Mデータセット)をインターネットから収集し、コントラスティブ学習で訓練されています。
AI画像生成(Stable Diffusion等)では、CLIPのテキストエンコーダ部分がプロンプトをベクトル化するために使われています。
先行研究と比べてどこがすごい?
従来のアプローチ(ImageNet事前学習)
- 固定された1,000カテゴリ(犬、猫、車など)で分類学習
- 新しいカテゴリには追加の学習データとファインチューニングが必要
- カテゴリに含まれない概念(「夕焼けに照らされた笑顔の女性」)は扱えない
CLIPのアプローチ
- 自然言語による柔軟な概念表現 — 任意のテキストで画像を記述可能
- ゼロショット転移 — 一度も見たことのないカテゴリも、テキストだけで認識できる
- ImageNetでResNet-50のゼロショット精度と同等 — 専用の学習なしで達成
- 30以上の視覚ベンチマーク(OCR、動画行動認識など)で競争力のある性能
技術や手法のキモはどこ?
コントラスティブ学習(Contrastive Learning)
CLIPの核心は、テキストと画像の対応関係をコントラスティブ学習で獲得する点です。
バッチ内のN個のテキスト-画像ペアに対して:
- 正例(positive): 対応するテキストと画像のペア → 類似度を最大化
- 負例(negative): 対応しないペア(N²-N組) → 類似度を最小化
これを対称的に(テキスト→画像、画像→テキストの両方向で)最適化します。
デュアルエンコーダ構造
| コンポーネント | 役割 | 出力 |
|---|---|---|
| テキストエンコーダ | テキストをベクトルに変換 | テキスト埋め込み(512次元) |
| 画像エンコーダ | 画像をベクトルに変換 | 画像埋め込み(512次元) |
- テキストエンコーダ: Transformer(GPTベース)
- 画像エンコーダ: Vision Transformer (ViT) または ResNet
両方の出力を同一のベクトル空間にマッピングし、コサイン類似度で比較します。
WIT-400Mデータセット
- インターネットから収集した4億組のテキスト-画像ペア
- ImageNetの130万枚と比べて300倍以上のスケール
- 多様な概念をカバー(写真、イラスト、グラフ、ミームなど)
75トークン制限の起源
CLIPのテキストエンコーダは最大77トークン(BOS/EOSトークンを含む)を処理します。実質的に使える部分は75トークンです。
Stable Diffusion系モデルでは、プロンプトが75トークンを超えるとチャンク分割されます。これがプロンプトの基本法則で述べた「先頭75トークンが最も重要」というルールの技術的な根拠です。
AI画像生成での役割
Stable Diffusion等のテキスト→画像モデルでは、CLIPは以下のように使われます:
ユーザーのプロンプト(テキスト)
↓
CLIPテキストエンコーダ → テキスト埋め込みベクトル
↓
Cross-Attention層(U-Netの中)で拡散過程を条件付け
↓
生成画像
つまり、CLIPはプロンプトと画像を繋ぐ橋渡し役です。
どうやって有効だと検証した?
ゼロショット評価
追加の学習データなしで、テキストプロンプトだけで画像分類を行いました。
| ベンチマーク | CLIPゼロショット精度 | 教師ありResNet-50 |
|---|---|---|
| ImageNet | 76.2% | 76.1% |
| ImageNet-V2 | 70.1% | 63.3% |
| ImageNet-Sketch | 60.2% | 24.8% |
特に注目すべきは分布シフトへのロバスト性です。ImageNet-V2(少し異なる条件の画像)やImageNet-Sketch(スケッチ画像)では、教師ありモデルよりもはるかに高い精度を示しています。
30+ベンチマーク
OCR、衛星画像認識、動画行動認識、地理位置推定など、多様なタスクで評価。多くのタスクで既存の専用モデルに匹敵する性能を達成しています。
議論はある?
制限事項
- タスク依存の性能バラツキ: 細粒度の分類(花の種類の区別など)ではまだ専用モデルに劣る
- プロンプトエンジニアリングの必要性: テキストの書き方によって結果が大きく変わる(「a photo of a {category}」のようなテンプレートが有効)
- 学習データのバイアス: インターネットから収集したデータには社会的バイアスが含まれる
- 抽象的な概念への弱さ: 「3個の物体がある画像」のような数量表現への対応が弱い
プロンプトの書き方への示唆
CLIPの学習データがWebから収集されたテキスト-画像ペアであることから、Web上でよく使われる表現(写真のキャプション、商品説明など)と相性が良い傾向があります。
これが「professional photography, 85mm lens」のようなカメラ用語がプロンプトで効果的な理由の一つです — CLIPの学習データに写真関連のキャプションが多く含まれているためです。
次に読むべき論文は?
| 論文 | 関連性 |
|---|---|
| ALIGN (Jia et al., 2021) | Googleによる類似のビジョン-言語事前学習。ノイズの多いデータでのスケーリング |
| Vision Transformer (ViT) (Dosovitskiy et al., 2020) | CLIPの画像エンコーダに使われるアーキテクチャ |
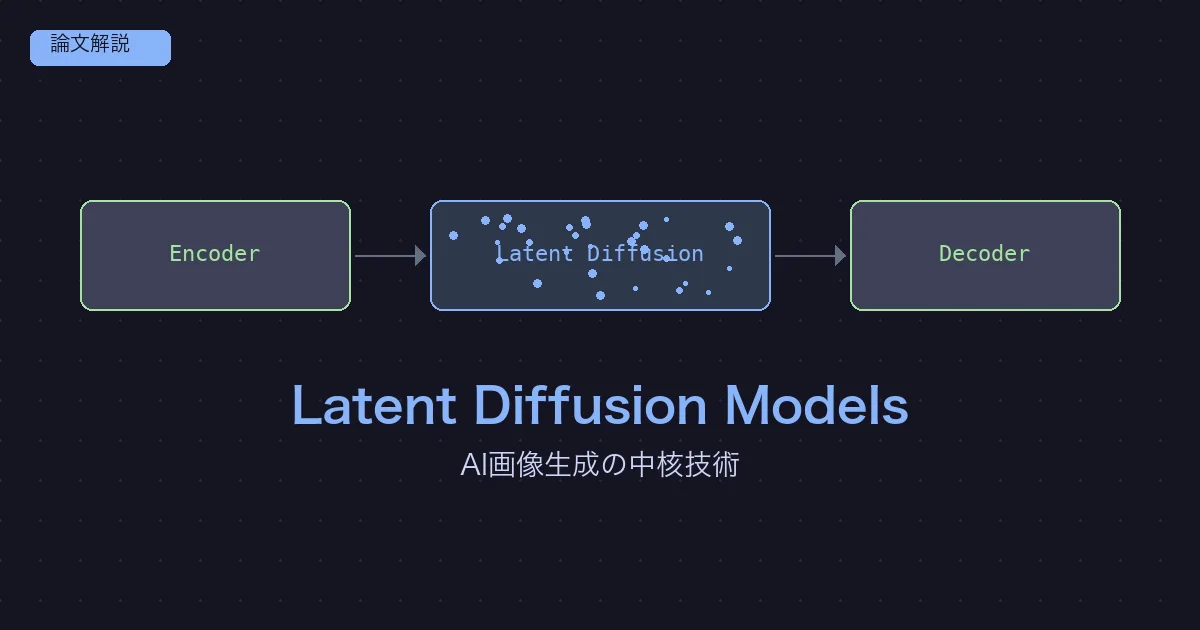
| Latent Diffusion Models (Rombach et al., 2022) | CLIPを画像生成に応用 → LDM論文解説 |
| Classifier-Free Diffusion Guidance (Ho & Salimans, 2022) | CLIPの埋め込みを使ったガイダンス → CFG論文解説 |
| OpenCLIP | CLIPのオープンソース再実装。LAION-5Bデータセットで訓練 |
この論文がAI画像生成に与えた影響
CLIPはテキストから画像を生成するすべてのモデルの基盤です。Stable Diffusion 1.x系ではCLIPのViT-L/14テキストエンコーダ、SDXL以降ではOpenCLIPが使われています。
プロンプトの書き方が画像品質に大きく影響する理由は、CLIPがテキストをどのようにベクトル化するかに依存しているからです。CLIPの理解なくして、効果的なプロンプト設計はありません。
関連記事
- プロンプトの基本法則 — CLIPに基づくプロンプトの語順ルール
- プロンプト設計の考え方 — CLIPの特性を活かしたプロンプト設計
- CFG論文解説 — CLIPの埋め込みをガイダンスに使う手法
- LDM論文解説 — CLIPをテキスト条件として組み込んだモデル